---
title: 基本原理
description: Git 基本原理
---
# 基本原理
本章将介绍一些 *Git* 和版本控制的背景知识,以便更好地理解 *Git* 的工作原理,加快后续章节的学习速度。
## 关于版本控制
> 版本控制(Version Control)是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
>
> [Pro Git book](https://git-scm.com/book/zh/v2/%E8%B5%B7%E6%AD%A5-%E5%85%B3%E4%BA%8E%E7%89%88%E6%9C%AC%E6%8E%A7%E5%88%B6)
在 [引入](./introduction) 的例子中,我们提到了彻夜修改代码却无法运行的事情。这种情况下,如果能够使用版本控制工具记录每次修改的内容,那么当出现问题时,就可以轻松地将整个项目回退到之前某个时间点的状态,但增加的工作量却微乎其微。更进一步,版本控制共工具还能够记录每次修改的作者、修改时间、修改原因等信息,这些信息对于项目的维护和管理非常有用。
以下是三种不同类型的版本控制系统:
将整个项目的目录复制下来,加上日期和其他信息,打包压缩成一个文件,然后存放在某个地方。一个最简单的版本控制系统就做好了。
但这种方式特别容易犯错,因为你必须手动完成所有的备份工作,而且很难对备份文件进行管理。所以会出现混淆备份文件、忘记备份备份文件丢失等问题。
于是人们基于此原理,开发了一些本地版本控制系统,用于自动化备份工作。
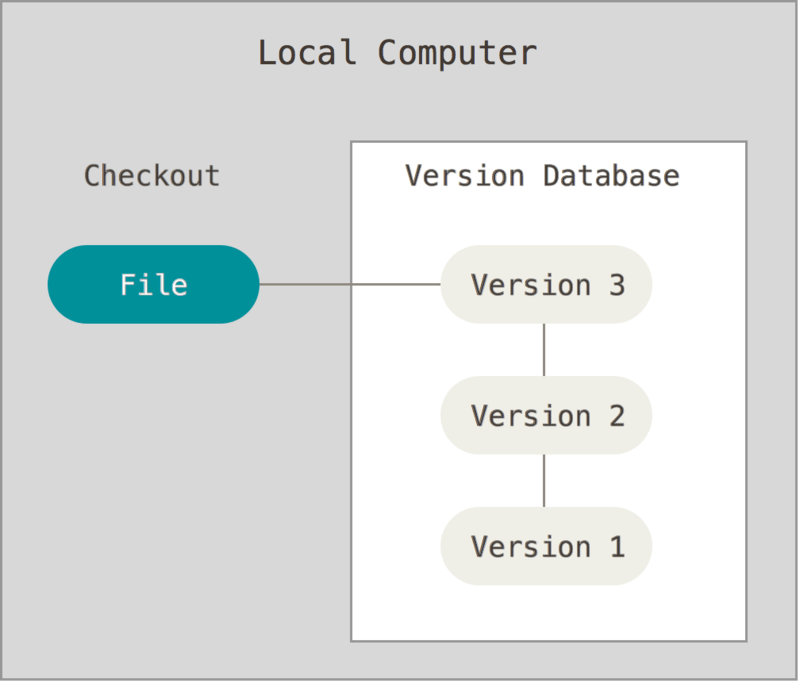
[source](https://git-scm.com/book/en/v2/images/local.png)
比较知名的本地版本控制系统有 *RCS*(Revision Control System),如今许多计算机系统上还有它的影子。*RCS* 的工作原是保存一个项目的补丁集(patch set),即每次修改的内容。当需要恢复到某个版本时,就将该版本之后的所有补丁依次应用,系统可以计算得出对应版本的内容了。
在本地版本控制系统的基础上,引入了一个中央服务器,用于存放所有的版本库。这样,集中化的版本控制系统就诞生了。每个人在本工作时,只需要将自己的修改同步到中央服务器,就可以与其他人共享修改了。
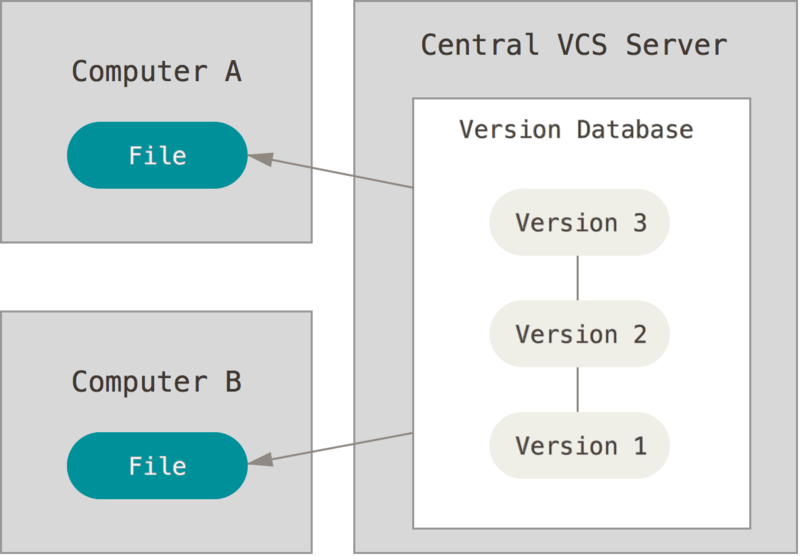[source](https://git-scm.com/book/en/v2/images/centralized.png)
常用的中心式版本控制系统有 *CVS*、*Subversion* 和 *Perforce*。 这类系统的优点是参与者可以清楚的了解其他人在做什么而且权限管理也极为方便。但该系统也有显而易见的缺点:中央服务器故障会导致所有人都无法工作,而且如果中央服务器的硬盘损坏所有的版本库都会丢失。
在前两种系统的基础上,人们发展出了分布式的版本控制系统,这类系统的每个参与者都拥有完整的版本库,而不是只有中央服务器拥完整的版本库。当新的参与者加入时,会将整个仓库完整的镜像下来,包括之前所有变更的历史记录。这样以来,即使用于协作的中央务器发送,之后都可以用其他参与者的本地仓库恢复。
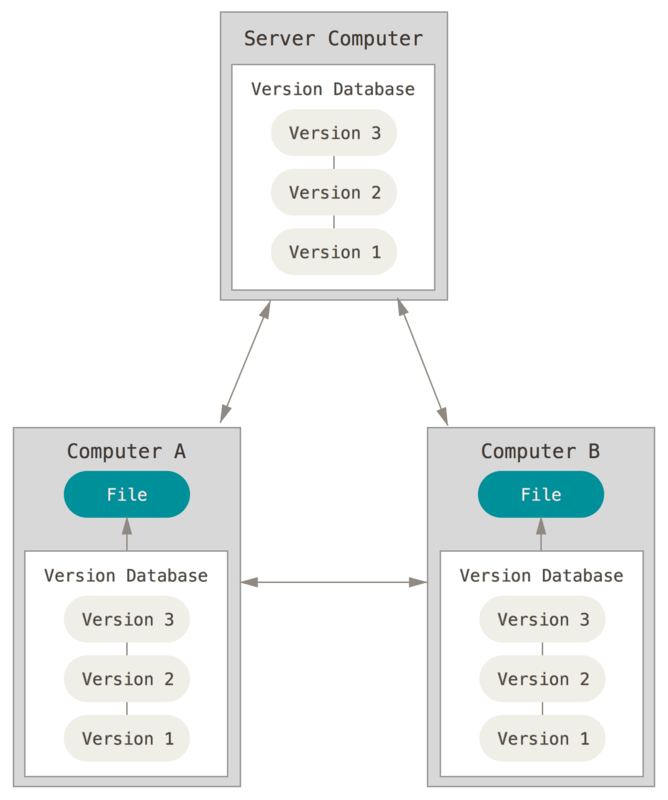
[source](https://git-scm.com/book/en/v2/images/distributed.png)
常见的分布式版本控制系统有 *Darcs*、*Mercurial* 以及著名的 *Git*。
在分布式的基础上,参与者可以根据需要在同个项目中实现多种的协作流程,使得工作管理更加灵活。
当然分布式系统也有很明显的缺点,比如学习曲线陡峭,需要更多时间和精力来掌握其工作原理和使用方法;代码安全性较低,每个参与都可以自由的查看和修改代码,需要额外的安全措施来保证项目代码的安全性。
## *Git* 核心思想
这句话描述的是 *Git* 与其他版本控制系统的最大区别,理解了这句话,使用起来才能知其所以然。下面来看两者的区别:
比较经典的版本控制系统(*CVS*、*Subversion* 等)采用的是**基于差异**的版本控制,即存储每个文件随时间累积的差异和原始文件。
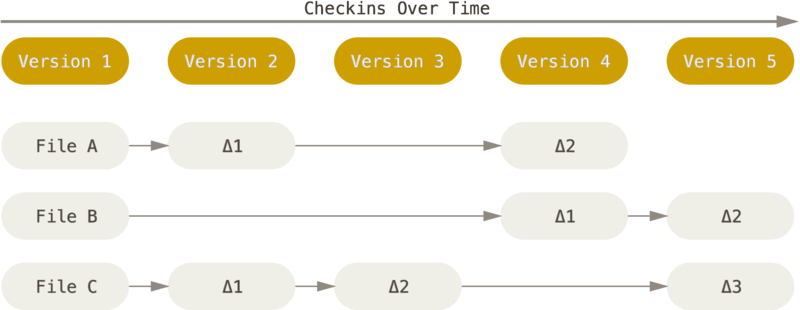
[source](https://git-scm.com/book/en/v2/images/deltas.png)
而 *Git* 则是采用**基于快照**的版本控制,即每次提交更新或保存状态时,对项目中的所有文件创建一个快照并储存其索引。特别的,当*Git* 检测到文件没有修改,则会直接链接到之前的文件,而不是再次储存一遍,以提高效率。
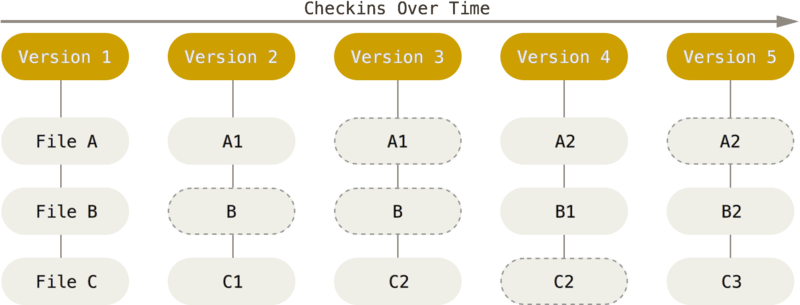
[source](https://git-scm.com/book/en/v2/images/snapshots.png)
在 *Git* 中,所有的数据在存储之前都会计算出校验和(checksum),在需要使用某数据时引用其校验和,而不是其文件名或者位置。这样一来,如果后续操作中,数据出现了损坏导致校验和不一致,*Git* 就能及时发现,从而保证了数据绝对的完整性。
这个功能构建在 *Git* 的底层,是 *Git* 核心思想不可或缺的一部分。(底层原理请参阅 “[Git 内部原理 - Git 对象](https://git-scm.com/book/zh/v2/Git-%E5%86%85%E9%83%A8%E5%8E%9F%E7%90%86-Git-%E5%AF%B9%E8%B1%A1)”)
在常用的 *Git* 操作中,几乎都是对数据库**做加法**(添加数据),很难对数据库**做减法**,也就是说 *Git* 几乎不会执行任何导致文件不可恢复的操作。一旦将更改提交到 *Git* 中,就很难再将该数据丢失,除非手动删除本地和远程的所有数据仓库。
这便是 *Git* 思想中的“反向奥卡姆剃刀”,即 **“如无必要,勿做减法”** 。在这种思想指导下,使用和探索 *Git* 成为了一个安心的过程,可以尽情做出各种尝试,而不必担心数据丢失的问题。
## 工作流程
为了便于后续内容的理解,我们先介绍 *Git* 工作流程中的三种状态:***已提交(committed)***、***已更改(modified)***和***已暂存(staged)***。
- 已更改:已更改表示在 *工作区* 中修改了文件,但还没有保存到数据库中。
- 已暂存:已暂存表示对一个已更改文件的当前版本做了标记并放入了 *暂存区*,使之包含在下次提交的快照中。
- 已提交:已提交表示数据已经安全的保存在本地数据库,即 **Git* 目录* 中 。
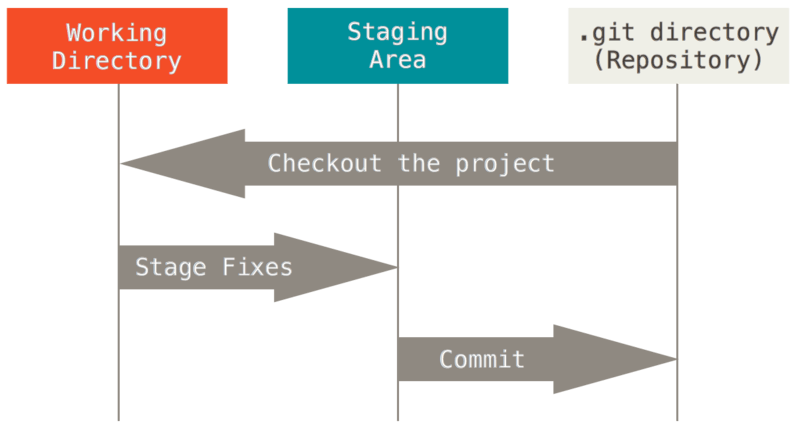
[source](https://git-scm.com/book/en/v2/images/areas.png)
- 工作区:存放项目实际文件的目录,即在电脑上看到的目录。
在工作区中,可以对文件进行修改、添加、删除等操作。这些操作只有在被提交至 *Git* 仓库后才会生效。
- 暂存区:介于工作区和仓库之间的缓冲区域,保存的是即将提交的文件索引(index)。
在工作区进行更改后,需要将更改的文件添加到暂存区,然后再提交到 *Git* 仓库中。
- *Git* 仓库:存放项目的版本控制数据的目录,即 `.git` 文件夹。
*Git* 仓库中保存了所有提交的历史记录,以及每次提交时的快照,是 *Git* 的核心。
---
*Git* 基本工作流程如下:
1. 在工作区中修改文件。
2. 选择需要暂存的更改,将其添加到暂存区。
3. 提交更改,将暂存区中的文件永久性的保存到 *Git* 仓库中。
为了更好理解,我们用比喻的方式来描述 *Git* 工作流程。
将Git的工作流程比作是一个厨房,我们在厨房里进行食材的加工和烹饪,就像在Git工作区中进行代码的修改和添加。
当我们觉得这些代码修改已经达到一定的程度时,可以将它们添加到Git暂存区,就像将备好的食材放在备餐台上一样,等待一起加工处理。
当暂存区中的代码足够多时,我们可以将它们提交到Git版本库中,就像将菜品做好后记录在菜谱中一样,形成一个完整的版本控制历史记录。
通过这种方式,我们可以更好地管理和控制代码的版本,避免频繁地提交和回滚代码,从而提高开发效率和代码质量。
## *Git* 基础操作
本节将介绍 *Git* 常用的基础操作,包括:获取 *Git* 仓库、记录更改、查看提交历史这三大部分。
具体的说,在本节的学习内容将涵盖以下方面:
- 如何初始化仓库(Repository)
- 如何跟踪(Track)文件的更改
- 如何将更改暂存(Stage)到暂存区
- 如何提交(Commit)更改到仓库
- 如何查看提交历史(Log)
- 如何比较不同提交之间的差异
> 以下内容会涉及到命令行操作,建议在学习前先了解一下“[命令行基础](../terminal/cli.md)”。
### 获取 *Git* 仓库
通常有两种方法来获取 *Git* 仓库:
1. **初始化(Init)**:将尚未被 *Git* 管理的本地目录转换为 *Git* 仓库。
2. **克隆(Clone)**:从其他服务器上获取一个已存在的 *Git* 仓库的拷贝。
#### 初始化 `git init`
初始化新仓库:
```bash
git init [repository name]
```
此命令会在当前目录下创建一个名为 `[repository name]` 的文件夹,并在其中创建一个 `.git` 文件夹,用于存放该 *Git* 仓库的版本控制数据。
---
另外一种方法是:在需要初始化的目录中执行 `git init` 命令,此时 *Git* 会在当前目录下创建一个 `.git` 文件夹。
输入 `cd [repository name]` 进入需要初始化的目录。
```bash
git init
```
同样的,该命令也会在当前目录下创建一个 `.git` 文件夹。
#### 克隆 `git clone`
克隆已有仓库:
```bash
git clone [repository url]
```
此命令会将远程仓库 `[repository url]` 克隆到当前目录下。
`[repository url]` 是 *Git* 仓库的 *URL*,即对应远程仓库的远程地址。
例如,要克隆本项目的仓库,可以执行以下命令:
```bash
git clone https://github.com/BPCClub/Shift2Modern.git
```
这会在当前目录下创建一个名为 `Shift2Modern` 的目录,并在其中创建一个 `.git` 文件夹,用于存放从远程仓库克隆下来的版本控制数据,再从其中读取最新版本的文件快照。
> 如需在克隆时自定义仓库名,请在末尾加上额外的参数 `[repository name]`。
> 例如:`git clone https://github.com/BPCClub/Shift2Modern.git [repository name]`
### 记录更改
在 *Git* 中,工作区文件的分为两种状态:***已跟踪(Tracked)*** 和 ***未跟踪(Untracked)***。
- 已跟踪:已经纳入 *Git* 版本控制的文件,包括已经暂存的文件和已经提交的文件,简单来说就是 *Git* 已经知道的文件。
- 未跟踪:尚未纳入 *Git* 版本控制的文件,这些可以是新创建的文件或已存在的文件,也可以是 `.gitignore` 中忽略的文件。总而言之,除了已跟踪文件之外的所有文件都是未跟踪文件。
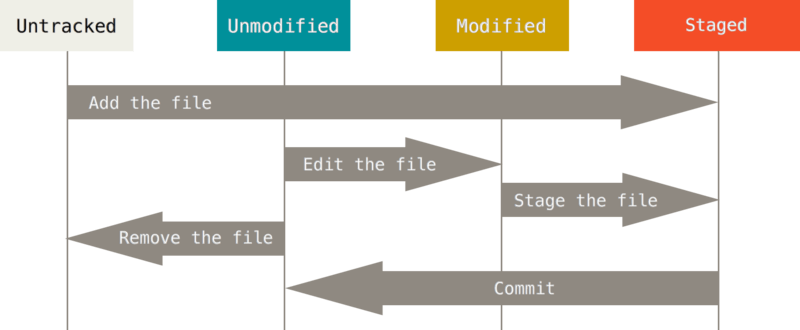
[source](https://git-scm.com/book/en/v2/images/lifecycle.png)
图中显示了文件可能的的状态变化周期,从左到右分别为:未跟踪、已跟踪、已暂存、已提交。
当已跟踪文件被修改后,*Git* 会将其标记为 ***已修改(Modified)*** 文件,可以选择性地将这些文件放入暂存区。
#### 查看状态 `git status`
要对文件进行各种操作,首先需要知道当前文件的状态。
```bash
git status
```
此命令会显示当前目录中 *Git* 的状态,包括:
- 当前所处分支
- 已跟踪文件的状态(是否被修改、暂存等)
- 未跟踪的文件
> `git status` 命令的输出结果十分详细,但在某些情况下,可能需要得到更简洁的输出结果。
> 通过 `git status -s` 命令来简化输出结果(简化后的文件状态代码需要查询 [*Git* 官方文档](https://git-scm.com/docs/git-status/zh_HANS-CN#_%E7%AE%80%E7%9F%AD%E6%A0%BC%E5%BC%8F) 来了解)。
#### 跟踪/暂存文件 `git add`
该指令可以将未跟踪文件变为已跟踪,也可以将已跟踪文件的更改添加到暂存区。
```bash
git add [file name]
```
对于未跟踪文件,此命令会将当前目录下的 `[file name]` 文件添加到 *Git* 的跟踪列表中。
若是已跟踪文件,则会将 `[file name]` 文件添加到 *Git* 的暂存区。
> 也可以使用 `git add .` 将当前目录下的所有文件添加到暂存区。
#### 提交文件 `git commit`
当所有的工作都完成后,便是将文件的更改提交到 *Git* 仓库,形成一次完整的版本控制历史记录。
```bash
git commit -m "[commit message]"
```
此命令会将暂存区中的文件提交到 *Git* 仓库,并附带一条提交信息 `[commit message]` 。
提交信息是对本次提交的简短描述,通常用于记录提交的更改内容。
> [为何要编写良好的提交信息](https://cbea.ms/git-commit/)
> [如何编写良好的提交信息](https://tbaggery.com/2008/04/19/a-note-about-git-commit-messages.html)
> 在提交之前,请务必使用 `git status` 检查是否有已修改的文件**尚未添加**到暂存区。如有,请对这些文件执行 `git add` ,否则这些文件的更改将不会被提交。
> 另一种办法是在提交时使用 `git commit -a`,将所有已跟踪文件暂存起来一并提交,从而跳过 `git add` 步骤。
## 回顾历史
### 查看提交历史 `git log`
在提交若干更改后,使用者可能会想要查看提交历史,以便了解自己的工作进展。需要在该项目目录内执行以下命令:
```bash
git log
```
此命令会显示当前 *Git* 仓库的提交历史,包括:
- 校验和
- 提交者信息
- 提交时间
- 提交信息
此时终端会进入 *Git* 的历史查看模式,该模式下按回车键可以查看更多的提交历史,按 `q` 键退出查看模式。
> 在未传入任何参数时,此命令会显示最近的提交历史。
> 可以在命令后添加 `-[number]` 来限制显示的提交历史数量,例如 `git log -3` 会显示最近的 3 条提交历史。
### 返回指定版本 `git reset`
返回指定版本:
```bash
git reset --hard [commit id]
```
此命令会将当前 *Git* 仓库的版本回退到指定版本。
> `[commit id]` 为提交历史中的提交 ID。
### 查看差异 `git diff`
以下命令能显示当前工作区尚未暂存的更改:
```bash
git diff
```
> 默认为工作区中的所有文件,如需指定文件,请添加可选参数 `[file]`。
有时可能会需要比较不同文件间的差异,下面列出几种常见情况以及对应的命令:
- 暂存区与上一次提交的差异
`git diff --staged [file]`
- 不同提交之间的差异
`git diff [commit id] [commit id] [file]]`
- 工作区和暂存区的更改与最新提交的差异
`git diff HEAD`
> 可以考虑使用 `git difftool` 命令来查看更加直观的差异。
> 详情请参阅“[*Git* 官方文档](https://git-scm.com/docs/git-difftool)”。